ShelPiはYOLOによる物体検出ができるため、特定のオブジェクトに対しアクションを行うといった制御が可能となっています。
よりグレードアップさせるために、手の動きを認識させてジェスチャー操作ができるか試してみました。
ChatGPTによると、MediaPipeというGoogleが提供している機械学習を用いたオープンソース・フレームワークというものがいいらしい。よくわかりませんが。
なにやらこれでハンドトラッキングができるようなので、早速試してみました。
MediaPipeは旧バージョンを使った方が簡単らしいので、仮想環境に以下のバージョンをインストールします。
pip install mediapipe==0.10.13
import cv2 import mediapipe as mp import requests import numpy as np mp_hands = mp.solutions.hands hands = mp_hands.Hands() mp_draw = mp.solutions.drawing_utils #カメラ映像取得 SHELPI_IP = "ShelpiのIPアドレス" SNAPSHOT_URL = f"http://{SHELPI_IP}:8080/?action=snapshot" def get_frame(): r = requests.get(SNAPSHOT_URL) img_arr = np.frombuffer(r.content, np.uint8) frame = cv2.imdecode(img_arr, cv2.IMREAD_COLOR) return frame while True: frame = get_frame() frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) results = hands.process(frame_rgb) if results.multi_hand_landmarks: if results.multi_hand_landmarks: for hand_idx, hand_landmarks in enumerate(results.multi_hand_landmarks): print(f"\n--- Hand {hand_idx} ---") for i, lm in enumerate(hand_landmarks.landmark): print(f"{i}: x={lm.x:.3f}, y={lm.y:.3f}, z={lm.z:.3f}") for handLms in results.multi_hand_landmarks: mp_draw.draw_landmarks(frame, handLms, mp_hands.HAND_CONNECTIONS) cv2.imshow("hand", frame) if cv2.waitKey(1) & 0xFF == 27: break
ShelPiはmjpg-streamerで映像をストリーミングしているので、それを取得して解析します。
実行すると、プレビューで手の骨格が表示され、ターミナルには各ポイントの座標が表示されます。
ShelPiのカメラをmjpg-streamerでストリーミングし、メインPCが映像を取得、MediaPipeで手を認識するかテスト。
— slowtech (@slowtech) 2026年4月5日
各ポイントの座標を取得できるので、ジェスチャーでShelPiを動かせそう。
YOLOと組み合わせればいろいろできるかも。#AI #MediaPipe #画像認識 pic.twitter.com/HXGOZMQFHb
かなり正確に骨格をトラッキングしているのが確認できました。
各ポイントのIDですが、
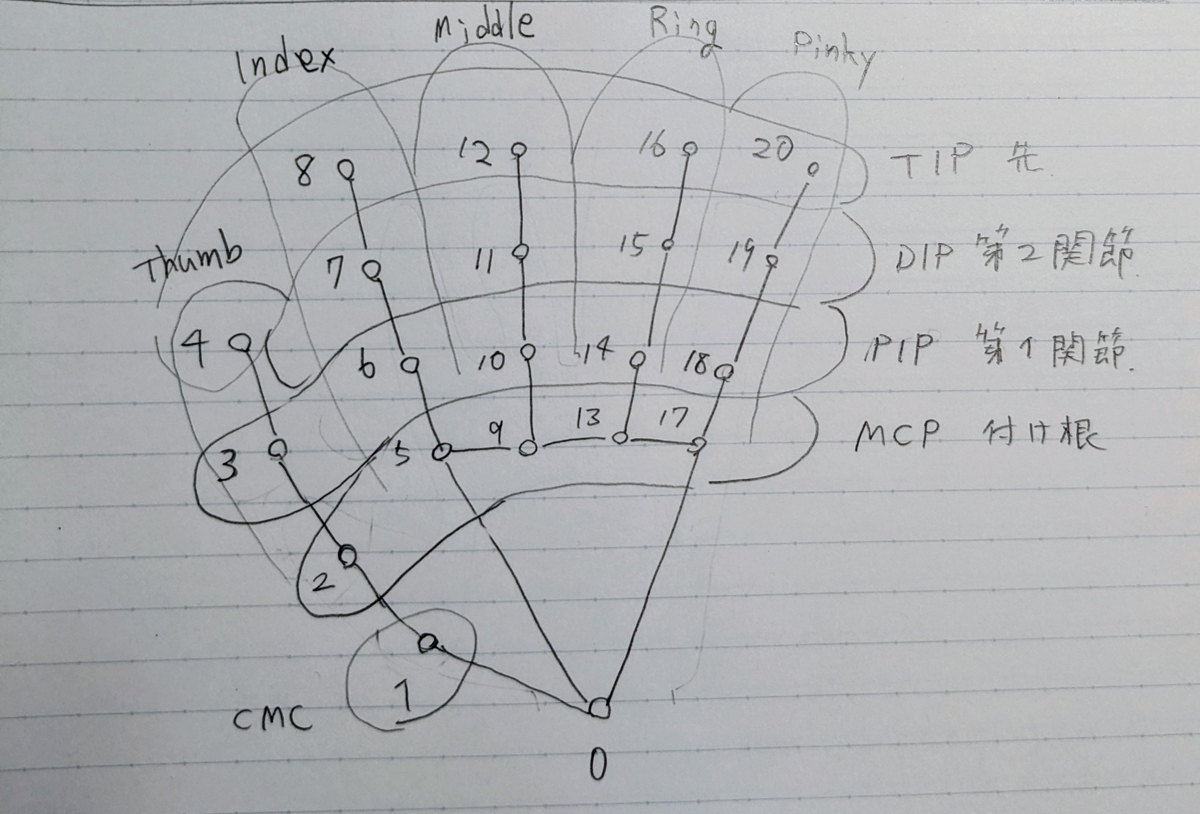
このようになっていて、各ポイントの座標の位置関係を比較してジェスチャーをプログラムしました。
グッドポーズ : じたばたして喜ぶ 手を振る : バイバイする 手の平を下にする : お手をする
ShelPiがジェスチャーを理解できるようになりました
— slowtech (@slowtech) 2026年4月5日
ShelPiカメラ→メインPC→MediaPipeで手の各ポイントの座標を取得→ジェスチャー名を送信→ShelPiが受け取りアクション実行
なかなか良いです#Robotics #AI #MediaPipe #ロボット #電子工作 pic.twitter.com/w9iqiltSm0
カメラの画角が狭くて、ロボットが動いているとなかなか認識させるのが大変でした。
広角カメラだともっといいんでしょうね。
でも、本格的なロボットになってきて満足です。



